
Download the full CDD Playbook - no email required.
Includes 5 guided activities that help conversational AI teams adopt conversation-driven development, and build the assistants users want.

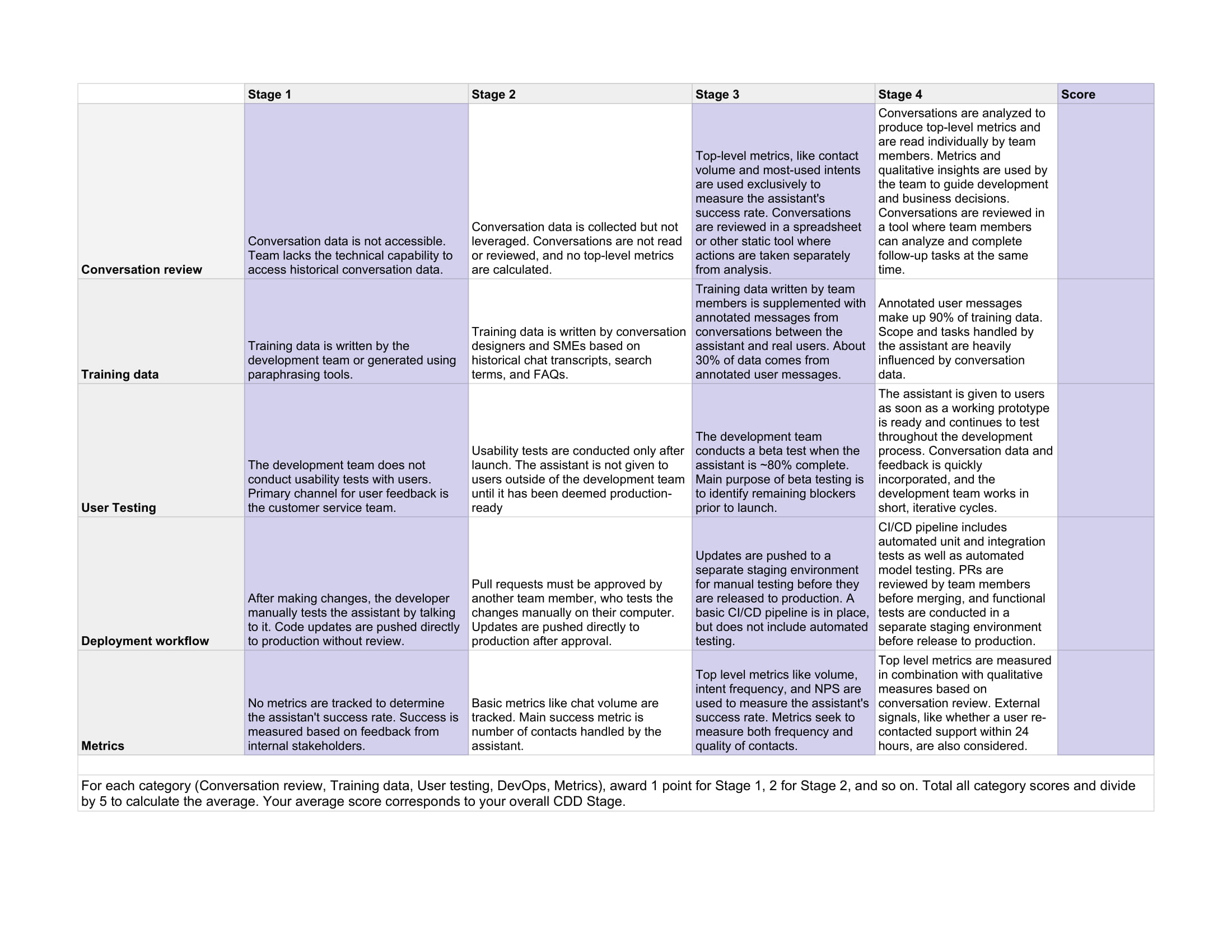
Before you can begin to align on a conversation-driven development as a team, it’s important to measure where your team stands today. We’ve created a scoring matrix to help you benchmark your team’s current practices and identify opportunities.
This play is designed to help your team come together on what CDD means and take a closer look at the habits and practices that are currently in place. This play can also help you prioritize which practices to work on and create a CDD roadmap for your team.
Play 1: Self Assessment

Materials:
CDD Scorecard Template
Time:
60 minutes
People:
1-10 participants
1 facilitator
Step 1: Discuss objectives
As the facilitator, set the stage for the discussion by providing background on conversation-driven development and outlining the goals for the session. Tie the discussion back to what your team hopes to accomplish with your assistant; for example, increasing your assistant’s accuracy or lowering the abandonment rate, or reducing incidents associated with deployment.
Step 2: Complete self-evaluations as a team
Give each team member a copy of the CDD Scorecard Template and allow 15-20 minutes for all participants to score the team. For each category (Conversation review, Training data, User testing, DevOps, Metrics), 1 point should be awarded for Stage 1, 2 for Stage 2, and so on. Participants should record their score for each category, total the category scores, and then divide by 5 to reach an average. Your average score corresponds to your overall CDD Stage.
Step 3: Share the self-evaluations
Each participant reports their scores to the group and shares first impressions. Pay close attention to categories where scores varied widely among participants and discuss why opinions differed.
Step 4: Determine next steps
Identify 1-2 areas where the team can improve their score. Brainstorm quick wins and pick one idea the team can put in place in the short term.
Discussion Questions
- How does the team decide which new intents and training examples should be added?
- Which success criteria is the assistant evaluated against?
- How often do deployments result in unexpected behavior or bugs?
- Are there any pain points around coming up with new training examples?
- How much access do team members have to first-hand user research?
- What is the current process for reviewing conversation data? Which tools are used to sort and prioritize conversations?
- How much context-switching is required when reviewing conversations and taking action based on what you’ve found?